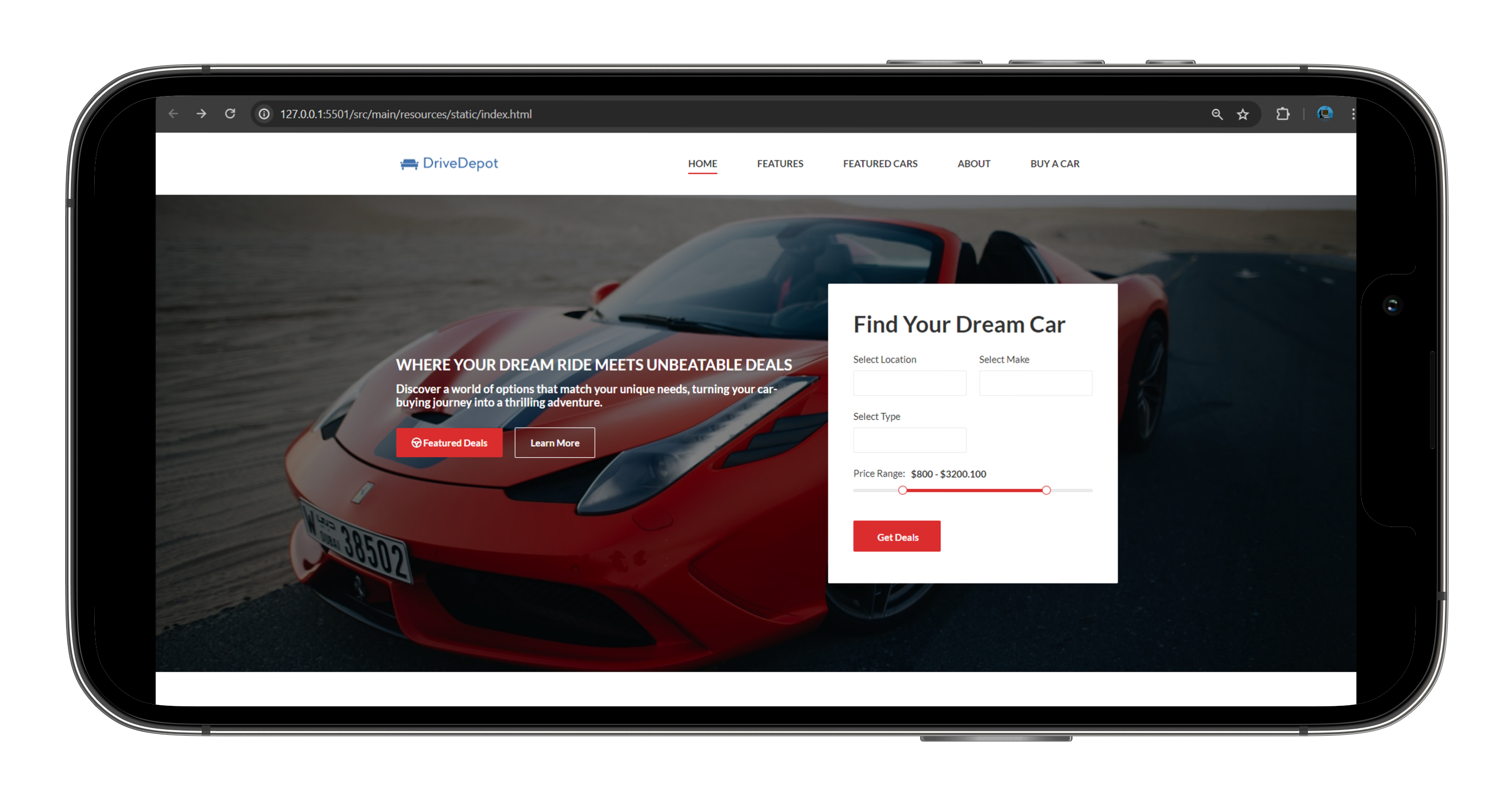
Welcome to the forefront of automotive decision-making with our Automobile Price Analysis software. Tailored for discerning users, this sophisticated tool not only meticulously analyzes and presents the best car deals but also goes beyond by offering a diverse array of options based on individual needs. Say goodbye to the complexities of car selection; our software is designed to seamlessly guide users toward their ideal vehicle, making the car-buying experience both intelligent and uniquely personalized.
Our cutting-edge car deals comparison platform utilises advanced web crawling and HTML parsing, to bring you the best car deals swiftly. DriveDepot leverages inverted indexing for quick searches. Features include page ranking, word completion, spell checking, finding patterns, search history and much more. Navigate effortlessly and find a perfect deal with our powerful feature-rich software.
We were shortlisted among the top 50 projects across the CS Department at the University of Windsor and showcased our innovation to a panel of judges from various renowned industry leaders at the CS Demo Day 2023.
Key-Feature Breakdown:
◦ Web crawler
◦ HTML parser
◦ Inverted indexing
◦ Frequency count
◦ Spell checking
◦ Word completion
◦ Search Frequency
◦ Data Validation using Regular Expressions
◦ Finding Patterns using Regular expression
◦ Page Ranking
◦ File-based indexing system
Implementation of few of the above features:
◦ Web crawler: Drive Depot uses Selenium for crawling data, Chrome Driver is used here by Selenium to control operations on
webpages residing on Chrome. It also uses JavaScript executor for enhanced interaction with web elements. For
optimized page loading, incorporated threads for managing the sleep intervals. Here while web crawling, data has
been crawled by interacting with various web page elements (popups, paginations, filters, images etc) to scrape
data and store the scraped data in files. The crawled data has been stored based on elements that includes the car
prices information. These files are then parsed and indexed.
Data Structures Used:
• TreeMap: For Handling various types of user inputs for locations, employed a TreeMap. It is configured for
case-insensitive ordering. The TreeMap is based on Red-Black trees and as it maintains keys in sorted order, it
is suitable for ordering keys in any order. As TreeMap implements ‘NavigableMap’ interface, this includes
finding the closest location (for mapping user’s input location to match an entry in the Map).
• TreeMap enables handling of different input formats for each website, like abbreviations, province names or
postal codes.
◦ Inverted indexing We used this to accelerates information retrieval, enhancing search efficiency by quickly pinpointing documents with specific keywords in search engines and databases.
Implementation: Tries involve mapping terms to page URLs using a Trie data structure. This implementation optimizes keyword-based document retrieval, enabling efficient and quick access to pages containing specific terms by traversing the Trie structure.
◦ Spell checking: Inorder to identify potential spelling mistakes and suggest corrections to users we used,
AVL trees for efficient storage and retrieval of words and employed Levenshtein distance(edit distance) algorithm for evaluating the similarity between words.
The AVL tree ensures fast access to words with logarithmic time complexity, while the Levenshtein distance
algorithm efficiently handles situations where a word is not found in the AVL tree.
◦ File-based indexing system: We store the parsed data is stored on to the file system. This has proven to be extremely beneficial in fetching data from a huge collection of cars in a matter of seconds! (EVEN FASTER THAN MOST OF THE DATABASE QUERY OPERATIONS!)
Considering Files are stored as large byte arrays onto the file system, the data while reading/writing to is being indexed by recording the number of bytes being used for each record along with the uniques of that record.
The indexes are being serialized to the File System, considering the data can be retrieved for subsequent runs.
Technologies Used:
◦ Java, XML, JavaScript
◦ Sprintboot, REST API's,
◦ HTML, CSS, SCSS, Angular
◦ Several Data Structures and algorithms to enhance effienciency